

一、Stream介绍
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
二、Stream创建
2.1 使用集合对象的stream方法构建流
1 | List<String> list = Arrays.asList("Java", "JavaScript", "python", "PHP", "C", "C++", "C#", "Golang", "Swift"); |
2.2 数值范围构建
IntStream和LongStream对象支持range和rangeClosed方法来构建数值流。这两个方法都是第一个参数接受起始值,第二个参数接受结束值。但range是不包含结束值的,而rangeClosed则包含结束值。
比如对10到20的整数求和:
1 | System.out.println(IntStream.range(10,20).sum()); //145 |
2.3 由值构建
静态方法Stream.of可以显式值创建一个流。它可以接受任意数量的参数。例如,以下代码直接使用Stream.of创建了一个字符串流:
1 | Stream<String> s = Stream.of("Java", "JavaScript", "python", "PHP", "C#", "Golang", "Swift"); |
也可以使用Stream.empty()构建一个空流:
1 | Stream<Object> o = Stream.empty(); |
2.4 由数组构建
静态方法Arrays.stream可以通过数组创建一个流。它接受一个数组作为参数。
1 | int[] arr = {1, 2, 3, 4, 5, 6, 7}; |
2.5 由文件生成流
java.nio.file.Files中的很多静态方法都会返回一个流。例如Files.lines方法会返回一个由指定文件中的各行构成的字符串流。比如统计一个文件中共有多少个字:
1 | long wordCout = 0L; |
2.6 由函数构造
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。这两个操作可以创建所谓的无限流。比如下面的例子构建了10个偶数:
1 | Stream.iterate(0, n -> n + 2).limit(10).forEach(System.out::println); |
iterate方法接受一个初始值(在这里是0),还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator类型)。这里,我们使用Lambda n -> n + 2,返回的是前一个元 素加上2。因此,iterate方法生成了一个所有正偶数的流:流的第一个元素是初始值0。然后加上2来生成新的值2,再加上2来得到新的值4,以此类推。
与iterate方法类似,generate方法也可让你按需生成一个无限流。但generate不是依次对每个新生成的值应用函数,比如下面的例子生成了5个0到1之间的随机双精度数:
1 | Stream.generate(Math::random).limit(5).forEach(System.out::println); |
0.23353383579369869
0.4108268031623806
0.4942831052728862
0.972680756534086
0.8616162073298483
三、流的操作介绍
流的使用一般包括三件事情:
一个数据源(如集合)来执行一个查询;
一个中间操作链,形成一条流的流水线;
一个终端操作,执行流水线,并能生成结果。
下表列出了流中常见的中间操作和终端操作:
| 操作 | 类型 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
|---|---|---|---|---|
| filter | 中间 | Stream | Predicate | T -> boolean |
| distinct | 中间 | Stream | ||
| skip | 中间 | Stream | long | |
| limit | 中间 | Stream | long | |
| map | 中间 | Stream | Function<T, R> | T -> R |
| flatMap | 中间 | Stream | Function<T, Stream | T -> Stream |
| sorted | 中间 | Stream | Comparator | (T, T) -> int |
| anyMatch | 终端 | boolean | Predicate | T -> boolean |
| noneMatch | 终端 | boolean | Predicate | T -> boolean |
| allMatch | 终端 | boolean | Predicate | T -> boolean |
| findAny | 终端 | Optional | ||
| findFirst | 终端 | Optional | ||
| forEach | 终端 | void | Consumer | T -> void |
| collect | 终端 | R | Collector<T, A, R> | |
| reduce | 终端 | Optional | BinaryOperator | (T, T) -> T |
| count | 终端 | long |
四、中间操作
下面的操作都会用到这个基础数据:
1 | List<String> list = Arrays.asList("Java", "JavaScript", "python", "PHP", "C", "C++", "C++", "C#", "Golang", "Swift"); |
4.1 filter
Streams接口支持·filter方法,该方法接收一个Predicate
1 | list.stream().filter(str -> str.contains("C")).forEach(System.out::println); |
结果输出:
C
C++
C++
C#
4.2 distinct
distinct方法用于排除流中重复的元素,类似于SQL中的distinct操作。比如筛选中集合中所有符合条件的数据,并排除重复的结果:
1 | list.stream().filter(str -> str.contains("C")).distinct().forEach(System.out::println); |
结果输出:
C
C++
C#
4.3 skip
skip(n)方法用于跳过流中的前n个元素,如果集合元素小于n,则返回空流。比如筛选出包含C的元素,并排除前两个:
1 | list.stream().filter(str -> str.contains("C")).skip(2).forEach(System.out::println); |
结果输出:
C++
C#
4.4 limit
limit(n)方法返回一个长度不超过n的流
1 | list.stream().filter(str -> str.contains("C")).limit(3).forEach(System.out::println); |
结果输出:
C
C++
C++
4.5 map
map方法接收一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素。如:
1 | list.stream().map(String::toLowerCase).forEach(System.out::println); |
结果输出:
java javascript python php c c++ c++ c# golang swift
map还支持将流特化为指定原始类型的流,如通过mapToInt,mapToDouble和mapToLong方法,可以将流转换为IntStream,DoubleStream和LongStream。特化后的流支持sum,min和max方法来对流中的元素进行计算。比如:
1 | Stream<Integer> lStr = list.stream().map(String::length); |
结果输出:
4 10 6 3 1 3 3 2 6 5
4.6 flatMap
flatMap用于将多个流合并成一个流,俗称流的扁平化。这么说有点抽象,举个例子,比如现在需要将list中的各个元素拆分为一个个字母,并过滤掉重复的结果,你可能会这样做:
结果输出:
J a v a J a v a S c r i p t p y t h o n P H P C C + + C + + C # G o l a n g S w i f t
五、终端操作
下面所有操作都会用到如下基础数据:
1 | List<String> list = Arrays.asList("Java", "JavaScript", "python", "PHP", "C", "C++", "C#", "Golang", "Swift"); |
5.1 anyMatch
anyMatch方法用于判断流中是否有符合判断条件的元素,返回值为boolean类型。比如判断list中是否含有Java字符的元素:
1 | System.out.println(list.stream().anyMatch(s -> s.contains("Java"))); //true |
5.2 allMatch
allMatch方法用于判断流中是否所有元素都满足给定的判断条件,返回值为boolean类型。比如判断list中是否所有元素长度都不大于10:
1 | System.out.println(list.stream().allMatch(s -> s.length() < 10)); //false |
5.3 noneMatch
noneMatch方法用于判断流中是否所有元素都不满足给定的判断条件,返回值为boolean类型。比如判断list中不存在长度大于10的元素:
1 | System.out.println(list.stream().noneMatch(s -> s.length() > 10)); //true |
5.4 findAny
findAny方法用于返回流中的任意元素的Optional类型,例如筛选出list中任意一个以J开头的元素,如果存在,则输出它:
1 | list.stream().filter(s->s.startsWith("J")).findAny().ifPresent(System.out::println); //Java |
5.5 findFirst
findFirst方法用于返回流中的第一个元素的Optional类型,例如筛选出list中长度大于5的元素,如果存在,则输出第一个:
1 | list.stream().filter(s->s.length()>5).findFirst().ifPresent(System.out::println); //JavaScript |
5.6 reduce
reduce函数从字面上来看就是压缩,缩减的意思,它可以用于数字类型的流的求和,求最大值和最小值。
1 | List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4); |
5.7 count
count方法用于统计流中元素的个数,比如:
1 | System.out.println(numbers.stream().count()); //7 |
5.8 forEach
forEach用于迭代流中的每个元素,最为常见的就是迭代输出,如:
1 | numbers.stream().forEach(s -> System.out.print(s+" ")); |
结果输出
1 2 1 3 3 2 4
5.9 collect
collect方法用于收集流中的元素,并放到不同类型的结果中,比如List、Set或者Map。举个例子:
1 | List<String> filterList = list.stream().filter(s -> s.startsWith("C")).collect(Collectors.toList()); |
六、并行流
6.1 并行流和顺序流差异
stream和parallelStream的简单区分:stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
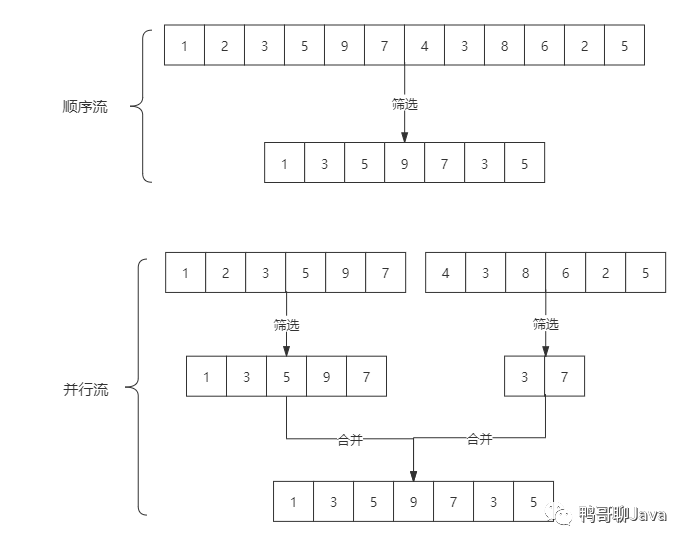
如果流中的数据量足够大,并行流可以加快处速度。除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
6.2 Optional
Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。更详细说明请见:菜鸟教程Java 8 Optional类。
七、数据收集
我们了解到终端操作collect方法用于收集流中的元素,并放到不同类型的结果中,比如List、Set或者Map。其实collect方法可以接受各种Collectors接口的静态方法作为参数来实现更为强大的规约操作,比如查找最大值最小值,汇总,分区和分组等等。
7.1 准备工作
为了演示Collectors接口中的静态方法使用,这里创建一个User类(人员类):
User.java
1 | @Data |
基础数据
1 | List<User> luser = new LinkedList<>(); |
7.2 遍历/匹配/筛选(foreach/find/match/filter)
Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。
1 | // 遍历输出符合条件的元素 |
结果输出:
User(id=1, userId=4100001, userName=001号, sex=true, area=陕西西安, cardId=6682393002323223131, performance=16000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)
User(id=2, userId=4100002, userName=002号, sex=true, area=陕西西安, cardId=6682393002323223132, performance=13500.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=0)
User(id=3, userId=4100003, userName=003号, sex=true, area=陕西咸阳, cardId=6682393002323223133, performance=12000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)
User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)
User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=0)
User(id=6, userId=4100006, userName=006号, sex=true, area=陕西宝鸡, cardId=6682393002323223136, performance=18350.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)
User(id=7, userId=4100007, userName=007号, sex=true, area=陕西渭南, cardId=6682393002323223137, performance=6000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)
User(id=8, userId=4100008, userName=008号, sex=true, area=陕西西安, cardId=6682393002323223138, performance=85000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=0)
findFirst---Optional[User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=1)]
findAny---Optional[User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 13:48:44 CST 2021, status=0)]
false
7.3 聚合(max/min/count)
1 | Optional<User> max = luser.stream().max(Comparator.comparingDouble(User::getPerformance)); |
输出:
员工业绩最大值:95000.0
陕西西安的人数: 3
7.4 映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
将员工的业绩全部增加1000
1 | // 不改变原来员工集合的方式 |
输出;
一次改动前:4100001-->16000.0
一次改动后:4100001-->17000.0
二次改动前:4100001-->17000.0
二次改动前:4100001-->17000.0
将两个字符数组合并成一个新的字符数组
1 | List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7"); |
输出:
处理前的集合:[m,k,l,a, 1,3,5,7]
处理后的集合:[m, k, l, a, 1, 3, 5, 7]
7.5 归约(reduce)
求所有人员的业绩之和和最高业绩
1 | // 求工资之和方式1: |
输出:
业绩之和:255850.0,255850,255850
最高业绩:95000,95000
7.6 归集(toList/toSet/toMap)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
下面用一个案例演示toList、toSet和toMap:
1 | Map<?, User> map = luser.stream().filter(p -> p.getPerformance() > 8000) |
输出:
toMap:{4100005=User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=0), 4100006=User(id=6, userId=4100006, userName=006号, sex=true, area=陕西宝鸡, cardId=6682393002323223136, performance=18350.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=1), 4100008=User(id=8, userId=4100008, userName=008号, sex=true, area=陕西西安, cardId=6682393002323223138, performance=85000.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=0), 4100001=User(id=1, userId=4100001, userName=001号, sex=true, area=陕西西安, cardId=6682393002323223131, performance=16000.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=1), 4100002=User(id=2, userId=4100002, userName=002号, sex=true, area=陕西西安, cardId=6682393002323223132, performance=13500.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=0), 4100003=User(id=3, userId=4100003, userName=003号, sex=true, area=陕西咸阳, cardId=6682393002323223133, performance=12000.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=1), 4100004=User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 14:39:16 CST 2021, status=1)}
7.7 统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
案例:统计员工人数、平均收入、收入总额、最高收入。
1 | // 求总数 |
输出:
员工总数:8
员工平均收入:31981.25
员工收入总和:255850.0
员工收入所有统计:DoubleSummaryStatistics{count=8, sum=255850.000000, min=6000.000000, average=31981.250000, max=95000.000000}
7.8 分组(partitioningBy/groupingBy)
分区:将stream按条件分为两个Map,比如员工按收入是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
将员工按收入是否高于15000分为两部分;将员工按性别和地区分组
1 | // 将员工按收入是否高于15000分组 |
输出:
员工按收入是否大于8000分组情况:{false=[User(id=2, userId=4100002, userName=002号, sex=true, area=陕西西安, cardId=6682393002323223132, performance=13500.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0), User(id=3, userId=4100003, userName=003号, sex=true, area=陕西咸阳, cardId=6682393002323223133, performance=12000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=7, userId=4100007, userName=007号, sex=true, area=陕西渭南, cardId=6682393002323223137, performance=6000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1)], true=[User(id=1, userId=4100001, userName=001号, sex=true, area=陕西西安, cardId=6682393002323223131, performance=16000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0), User(id=6, userId=4100006, userName=006号, sex=true, area=陕西宝鸡, cardId=6682393002323223136, performance=18350.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=8, userId=4100008, userName=008号, sex=true, area=陕西西安, cardId=6682393002323223138, performance=85000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0)]}
员工按性别分组情况:{true=[User(id=1, userId=4100001, userName=001号, sex=true, area=陕西西安, cardId=6682393002323223131, performance=16000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=2, userId=4100002, userName=002号, sex=true, area=陕西西安, cardId=6682393002323223132, performance=13500.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0), User(id=3, userId=4100003, userName=003号, sex=true, area=陕西咸阳, cardId=6682393002323223133, performance=12000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0), User(id=6, userId=4100006, userName=006号, sex=true, area=陕西宝鸡, cardId=6682393002323223136, performance=18350.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=7, userId=4100007, userName=007号, sex=true, area=陕西渭南, cardId=6682393002323223137, performance=6000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=8, userId=4100008, userName=008号, sex=true, area=陕西西安, cardId=6682393002323223138, performance=85000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0)]}
员工按性别、地区:{true={陕西咸阳=[User(id=3, userId=4100003, userName=003号, sex=true, area=陕西咸阳, cardId=6682393002323223133, performance=12000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=5, userId=4100005, userName=005号, sex=true, area=陕西咸阳, cardId=6682393002323223135, performance=95000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0)], 陕西宝鸡=[User(id=4, userId=4100004, userName=004号, sex=true, area=陕西宝鸡, cardId=6682393002323223134, performance=10000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=6, userId=4100006, userName=006号, sex=true, area=陕西宝鸡, cardId=6682393002323223136, performance=18350.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1)], 陕西渭南=[User(id=7, userId=4100007, userName=007号, sex=true, area=陕西渭南, cardId=6682393002323223137, performance=6000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1)], 陕西西安=[User(id=1, userId=4100001, userName=001号, sex=true, area=陕西西安, cardId=6682393002323223131, performance=16000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=1), User(id=2, userId=4100002, userName=002号, sex=true, area=陕西西安, cardId=6682393002323223132, performance=13500.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0), User(id=8, userId=4100008, userName=008号, sex=true, area=陕西西安, cardId=6682393002323223138, performance=85000.0, createTime=Mon Aug 30 14:52:01 CST 2021, status=0)]}}
7.9 接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
1 | String names = luser.stream().map(p -> p.getUserName()).collect(Collectors.joining(",")); |
输出:
所有员工的姓名:001号,002号,003号,004号,005号,006号,007号,008号
拼接后的字符串:A-B-C
7.10 归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
1 | // 每个员工减去起征点后的薪资之和(这个例子并不严谨,但一时没想到好的例子) |
输出:
员工扣税薪资总和:215850
员工薪资总和:255850.0
7.11 排序(sorted)
sorted,中间操作。有两种排序:
sorted():自然排序,流中元素需实现Comparable接口
sorted(Comparator com):Comparator排序器自定义排序
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
1 | // 按收入升序排序(自然排序) |
输出:
按收入升序排序:[007号, 004号, 003号, 002号, 001号, 006号, 008号, 005号]
按收入降序排序:[005号, 008号, 006号, 001号, 002号, 003号, 004号, 007号]
先按收入再按ID升序排序:[007号, 004号, 003号, 002号, 001号, 006号, 008号, 005号]
先按收入再按ID自定义降序排序:[005号, 008号, 006号, 001号, 002号, 003号, 004号, 007号]
7.12 提取/组合
流也可以进行合并、去重、限制、跳过等操作。
1 | String[] arr1 = { "a", "b", "c", "d" }; |
输出:
流合并:[a, b, c, d, e, f, g]
limit:[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
skip:[3, 5, 7, 9, 11]

