一、 REPL(交互式解释器)
Node.js REPL(Read Eval Print Loop:交互式解释器) 表示一个电脑的环境,类似 Window 系统的终端或 Unix/Linux shell,我们可以在终端中输入命令,并接收系统的响应。
1.1 作用
Node 自带了交互式解释器,可以执行以下任务:
读取 - 读取用户输入,解析输入了Javascript 数据结构并存储在内存中。
执行 - 执行输入的数据结构
打印 - 输出结果
循环 - 循环操作以上步骤直到用户两次按下 ctrl-c 按钮退出。
Node 的交互式解释器可以很好的调试 Javascript 代码。
1.2 基本使用
我们可以输入以下命令来启动 Node 的终端:
C:\Users\wno704>node
Welcome to Node.js v14.13.1.
Type ".help" for more information.
1.3 简单的表达式运算
1 | > 1+4 |
1.4 使用变量
你可以将数据存储在变量中,并在你需要的时候使用它。
变量声明需要使用 var 关键字,如果没有使用 var 关键字变量会直接打印出来。
使用 var 关键字的变量可以使用 console.log() 来输出变量。
1 | > x=10 |
1.5 多行表达式
Node REPL 支持输入多行表达式,这就有点类似 JavaScript。接下来让我们来执行一个 do-while 循环:
1 | > var x=0 |
... 三个点的符号是系统自动生成的,你回车换行后即可。Node 会自动检测是否为连续的表达式。
1.6 下划线(_)变量
你可以使用下划线(_)获取上一个表达式的运算结果:
1 | > var x=10 |
1.7 REPL 命令
ctrl + c : 退出当前终端。
ctrl + c 按下两次 : 退出 Node REPL。
ctrl + d : 退出 Node REPL.
??/?? : 查看输入的历史命令
tab : 列出当前命令
.help : 列出使用命令
.break : 退出多行表达式
.clear : 退出多行表达式
.save filename : 保存当前的 Node REPL 会话到指定文件
.load filename : 载入当前 Node REPL 会话的文件内容。
二、回调函数
Node.js 异步编程的直接体现就是回调。
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
例如,我们可以一边读取文件,一边执行其他命令,在文件读取完成后,我们将文件内容作为回调函数的参数返回。这样在执行代码时就没有阻塞或等待文件 I/O 操作。这就大大提高了 Node.js 的性能,可以处理大量的并发请求。
回调函数一般作为函数的最后一个参数出现:
1 | function foo1(name, age, callback) { } |
2.1 阻塞代码实例
创建一个文件 input.txt ,内容如下:
1 | 异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。 |
创建 sync.js 文件, 代码如下:
1 | var fs = require('fs'); |
以上代码执行结果如下:
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
程序执行结束!
2.2 非阻塞代码实例
创建 async.js 文件, 代码如下:
1 | var fs = require("fs"); |
以上代码执行结果如下:
程序执行结束!
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
以上两个实例我们了解了阻塞与非阻塞调用的不同。第一个实例在文件读取完后才执行程序。 第二个实例我们不需要等待文件读取完,这样就可以在读取文件时同时执行接下来的代码,大大提高了程序的性能。
因此,阻塞是按顺序执行的,而非阻塞是不需要按顺序的,所以如果需要处理回调函数的参数,我们就需要写在回调函数内。
三、事件循环
Node.js 是单进程单线程应用程序,但是因为 V8 引擎提供的异步执行回调接口,通过这些接口可以处理大量的并发,所以性能非常高。
Node.js 几乎每一个 API 都是支持回调函数的。
Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现。
Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件观察者退出,每个异步事件都生成一个事件观察者,如果有事件发生就调用该回调函数.
3.1 事件驱动程序
Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。
当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
这个模型非常高效可扩展性非常强,因为 webserver 一直接受请求而不等待任何读写操作。(这也称之为非阻塞式IO或者事件驱动IO)
在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。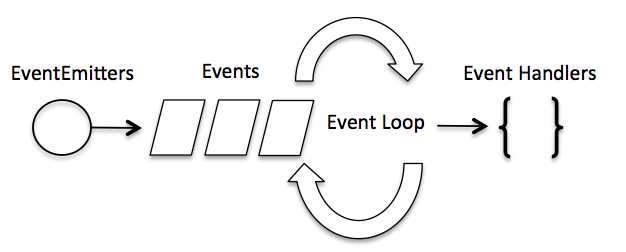
整个事件驱动的流程就是这么实现的,非常简洁。有点类似于观察者模式,事件相当于一个主题(Subject),而所有注册到这个事件上的处理函数相当于观察者(Observer)。
Node.js 有多个内置的事件,我们可以通过引入 events 模块,并通过实例化 EventEmitter 类来绑定和监听事件,如下实例:
1 | // 引入 events 模块 |
以下程序绑定事件处理程序:
1 | // 绑定事件及事件的处理程序 |
我们可以通过程序触发事件:
1 | // 触发事件 |
3.2 实例
创建 events.js 文件,代码如下所示:
1 | // 引入 events 模块 |
接下来让我们执行以上代码:
连接成功。
数据接收成功。
程序执行完毕。
3.3 Node 应用程序是如何工作的?
在 Node 应用程序中,执行异步操作的函数将回调函数作为最后一个参数, 回调函数接收错误对象作为第一个参数。
接下来让我们来重新看下前面的实例,创建一个 input.txt ,文件内容如下:
修改 events.js 文件,代码如下:
1 | var fs = require("fs"); |
以上程序中 fs.readFile() 是异步函数用于读取文件。 如果在读取文件过程中发生错误,错误 err 对象就会输出错误信息。
如果没发生错误,readFile 跳过 err 对象的输出,文件内容就通过回调函数输出。
执行以上代码,执行结果如下:
程序执行完毕
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
接下来我们读取 input1.txt 文件,执行结果如下所示:
因为文件 input1.txt 不存在,所以输出了错误信息。
程序执行完毕
Error: ENOENT: no such file or directory, open 'E:\workspace\workspace(nodejs)\day01\input1.txt'
四、EventEmitter
Node.js 所有的异步 I/O 操作在完成时都会发送一个事件到事件队列。
Node.js 里面的许多对象都会分发事件:一个 net.Server 对象会在每次有新连接时触发一个事件, 一个 fs.readStream 对象会在文件被打开的时候触发一个事件。 所有这些产生事件的对象都是 events.EventEmitter 的实例。
4.1 EventEmitter 类
events 模块只提供了一个对象: events.EventEmitter。EventEmitter 的核心就是事件触发与事件监听器功能的封装。
你可以通过require("events");来访问该模块。
1 | // 引入 events 模块 |
EventEmitter 对象如果在实例化时发生错误,会触发 error 事件。当添加新的监听器时,newListener 事件会触发,当监听器被移除时,removeListener 事件被触发。
下面我们用一个简单的例子说明 EventEmitter 的用法:
1 | //event.js 文件 |
执行结果如下:
some_event 事件触发
运行这段代码,1 秒后控制台输出了 'some_event 事件触发'。其原理是 event 对象注册了事件 some_event 的一个监听器,然后我们通过 setTimeout 在 1000 毫秒以后向 event 对象发送事件 some_event,此时会调用some_event 的监听器。
EventEmitter 的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的语义。对于每个事件,EventEmitter 支持 若干个事件监听器。
当事件触发时,注册到这个事件的事件监听器被依次调用,事件参数作为回调函数参数传递。
让我们以下面的例子解释这个过程:
1 | //event.js 文件 |
执行以上代码,运行的结果如下:
listener1 arg1 参数 arg2 参数
listener2 arg1 参数 arg2 参数
以上例子中,emitter 为事件 someEvent 注册了两个事件监听器,然后触发了 someEvent 事件。
运行结果中可以看到两个事件监听器回调函数被先后调用。 这就是EventEmitter最简单的用法。
EventEmitter 提供了多个属性,如 on 和 emit。on 函数用于绑定事件函数,emit 属性用于触发一个事件。接下来我们来具体看下 EventEmitter 的属性介绍。
4.2 属性介绍
| 类型 | 方法 | 描述 |
|---|---|---|
| 方法 | addListener(event, listener) | 为指定事件添加一个监听器到监听器数组的尾部。 |
| 方法 | on(event, listener) | 为指定事件注册一个监听器,接受一个字符串 event 和一个回调函数。 |
| 方法 | once(event, listener) | 为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器。 |
| 方法 | removeListener(event, listener) | 移除指定事件的某个监听器,监听器必须是该事件已经注册过的监听器。它接受两个参数,第一个是事件名称,第二个是回调函数名称。 |
| 方法 | removeAllListeners([event]) | 移除所有事件的所有监听器, 如果指定事件,则移除指定事件的所有监听器。 |
| 方法 | setMaxListeners(n) | 默认情况下, EventEmitters 如果你添加的监听器超过 10 个就会输出警告信息。 setMaxListeners 函数用于提高监听器的默认限制的数量。 |
| 方法 | listeners(event) | 返回指定事件的监听器数组。 |
| 方法 | emit(event, [arg1], [arg2], [...]) | 按监听器的顺序执行执行每个监听器,如果事件有注册监听返回 true,否则返回 false。 |
| 类方法 | listenerCount(emitter, event) | 返回指定事件的监听器数量。 |
| 事件 | newListener event - 字符串,事件名称, listener - 处理事件函数 | 该事件在添加新监听器时被触发。 |
| 事件 | removeListener event - 字符串,事件名称, listener - 处理事件函数 | 从指定监听器数组中删除一个监听器。需要注意的是,此操作将会改变处于被删监听器之后的那些监听器的索引。 |
4.3 实例
以下实例通过 connection(连接)事件演示了 EventEmitter 类的应用。
创建 event1.js 文件,代码如下:
1 | var events = require('events'); |
以上代码,执行结果如下所示:
2 个监听器监听连接事件。
监听器 listener1 执行。
监听器 listener2 执行。
listener1 不再受监听。
监听器 listener2 执行。
1 个监听器监听连接事件。
程序执行完毕。
4.4 error 事件
EventEmitter 定义了一个特殊的事件 error,它包含了错误的语义,我们在遇到 异常的时候通常会触发 error 事件。
当 error 被触发时,EventEmitter 规定如果没有响 应的监听器,Node.js 会把它当作异常,退出程序并输出错误信息。
我们一般要为会触发 error 事件的对象设置监听器,避免遇到错误后整个程序崩溃。例如:
1 | var events = require('events'); |
运行时会显示以下错误:
1 | events.js:305 |
4.5 继承 EventEmitter
大多数时候我们不会直接使用 EventEmitter,而是在对象中继承它。包括 fs、net、 http 在内的,只要是支持事件响应的核心模块都是 EventEmitter 的子类。
为什么要这样做呢?原因有两点:
首先,具有某个实体功能的对象实现事件符合语义, 事件的监听和发生应该是一个对象的方法。
其次 JavaScript 的对象机制是基于原型的,支持 部分多重继承,继承 EventEmitter 不会打乱对象原有的继承关系。
五、Buffer(缓冲区)
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
在v6.0之前创建Buffer对象直接使用new Buffer()构造函数来创建对象实例,但是Buffer对内存的权限操作相比很大,可以直接捕获一些敏感信息,所以在v6.0以后,官方文档里面建议使用 Buffer.from() 接口去创建Buffer对象。
5.1 Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
1 | const buf = Buffer.from('wno704', 'ascii'); |
Node.js 目前支持的字符编码包括:
| 编码 | 解释 |
|---|---|
| ascii | 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。 |
| utf8 | 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。 |
| utf16le | 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。 |
| ucs2 | utf16le 的别名。 |
| base64 | Base64 编码。 |
| latin1 | 一种把 Buffer 编码成一字节编码的字符串的方式。 |
| binary | latin1 的别名。 |
| hex | 将每个字节编码为两个十六进制字符。 |
5.2 创建 Buffer 类
Buffer 提供了以下 API 来创建 Buffer 类:
| 方法 | 解释 |
|---|---|
| Buffer.alloc(size[, fill[, encoding]]) | 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0 |
| Buffer.allocUnsafe(size) | 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据 |
| Buffer.allocUnsafeSlow(size) | |
| Buffer.from(array) | 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖) |
| Buffer.from(arrayBuffer[, byteOffset[, length]]) | 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。 |
| Buffer.from(buffer) | 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例 |
| Buffer.from(string[, encoding]) | 返回一个被 string 的值初始化的新的 Buffer 实例 |
示例
1 | // 创建一个长度为 10、且用 0 填充的 Buffer。 |
5.3 写入缓冲区
语法
buf.write(string[, offset[, length]][, encoding])
参数
参数描述如下:
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。 length 参数是写入的字节数。 如果 buf 没有足够的空间保存整个字符串,则只会写入 string 的一部分。 只部分解码的字符不会被写入。
返回值
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
实例
1 | buf = Buffer.alloc(256); |
执行以上代码,输出结果为:
写入字节数 : 14
5.4 从缓冲区读取数据
语法
buf.toString([encoding[, start[, end]]])
参数
参数描述如下:
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
返回值
解码缓冲区数据并使用指定的编码返回字符串。
实例
1 | //------从缓冲区读取数据 |
执行以上代码,输出结果为:
abcdefghijklmnopqrstuvwxyz
abcde
abcde
abcde
5.5 将Buffer转换为JSON对象
语法
buf.toJSON()
当字符串化一个 Buffer 实例时,JSON.stringify() 会隐式地调用该 toJSON()。
返回值
返回 JSON 对象。
实例
1 | const buf = Buffer.from([0x1, 0x2, 0x3, 0x4, 0x5]); |
执行以上代码,输出结果为:
{"type":"Buffer","data":[1,2,3,4,5]}
<Buffer 01 02 03 04 05>
5.6 缓冲区合并
语法
Buffer.concat(list[, totalLength])
参数
参数描述如下:
list - 用于合并的 Buffer 对象数组列表。
totalLength - 指定合并后Buffer对象的总长度。
返回值
返回一个多个成员合并的新 Buffer 对象。
实例
1 | var buffer1 = Buffer.from(('wno704')); |
执行以上代码,输出结果为:
buffer3 内容 : wno704www.wno704.com
5.7 缓冲区比较
语法
buf.compare(otherBuffer);
参数
参数描述如下:
otherBuffer - 与 buf 对象比较的另外一个 Buffer 对象。
返回值
返回一个数字,表示 buf 在 otherBuffer 之前,之后或相同。
实例
1 | var buffer1 = Buffer.from('ABC'); |
执行以上代码,输出结果为:
ABC 在 ABCD之前
5.8 拷贝缓冲区
语法
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
参数
参数描述如下:
targetBuffer - 要拷贝的 Buffer 对象。
targetStart - 数字, 可选, 默认: 0
sourceStart - 数字, 可选, 默认: 0
sourceEnd - 数字, 可选, 默认: buffer.length
返回值
没有返回值。
实例
1 | var buf1 = Buffer.from('abcdefghijkl'); |
执行以上代码,输出结果为:
abRUNOOBijkl
5.9 缓冲区裁剪
语法
buf.slice([start[, end]])
参数
参数描述如下:
start - 数字, 可选, 默认: 0
end - 数字, 可选, 默认: buffer.length
返回值
返回一个新的缓冲区,它和旧缓冲区指向同一块内存,但是从索引 start 到 end 的位置剪切。
实例
1 | var buffer1 = Buffer.from('wno704'); |
执行以上代码,输出结果为:
buffer2 content: wno
5.10 缓冲区长度
语法
buf.length;
返回值
返回 Buffer 对象所占据的内存长度。
实例
var buffer1 = Buffer.from('wno704');
// 剪切缓冲区
var buffer2 = buffer1.slice(0,3);
console.log("buffer2 content: " + buffer2.toString());
执行以上代码,输出结果为:
buffer2 content: wno
5.11 方法参考手册
| 方法 | 描述 |
|---|---|
| new Buffer(size) | 分配一个新的 size 大小单位为8位字节的 buffer。 注意, size 必须小于 kMaxLength,否则,将会抛出异常 RangeError。废弃的: 使用 Buffer.alloc() 代替(或 Buffer.allocUnsafe())。 |
| new Buffer(buffer) | 拷贝参数 buffer 的数据到 Buffer 实例。废弃的: 使用 Buffer.from(buffer) 代替。 |
| new Buffer(str[, encoding]) | 分配一个新的 buffer ,其中包含着传入的 str 字符串。 encoding 编码方式默认为 'utf8'。 废弃的: 使用 Buffer.from(string[, encoding]) 代替。 |
| buf.length | 返回这个 buffer 的 bytes 数。注意这未必是 buffer 里面内容的大小。length 是 buffer 对象所分配的内存数,它不会随着这个 buffer 对象内容的改变而改变。 |
| buf.write(string[, offset[, length]][, encoding]) | 根据参数 offset 偏移量和指定的 encoding 编码方式,将参数 string 数据写入buffer。 offset 偏移量默认值是 0, encoding 编码方式默认是 utf8。 length 长度是将要写入的字符串的 bytes 大小。 返回 number 类型,表示写入了多少 8 位字节流。如果 buffer 没有足够的空间来放整个 string,它将只会只写入部分字符串。 length 默认是 buffer.length - offset。 这个方法不会出现写入部分字符。 |
| buf.writeUIntLE(value, offset, byteLength[, noAssert]) | 将 value 写入到 buffer 里, 它由 offset 和 byteLength 决定,最高支持 48 位无符号整数,小端对齐。 |
| buf.writeUIntBE(value, offset, byteLength[, noAssert]) | 将 value 写入到 buffer 里, 它由 offset 和 byteLength 决定,最高支持 48 位无符号整数,大端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| buf.writeIntLE(value, offset, byteLength[, noAssert]) | 将value 写入到 buffer 里, 它由offset 和 byteLength 决定,最高支持48位有符号整数,小端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| buf.writeIntBE(value, offset, byteLength[, noAssert]) | 将value 写入到 buffer 里, 它由offset 和 byteLength 决定,最高支持48位有符号整数,大端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| buf.readUIntLE(offset, byteLength[, noAssert]) | 支持读取 48 位以下的无符号数字,小端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| buf.readUIntBE(offset, byteLength[, noAssert]) | 支持读取 48 位以下的无符号数字,大端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| buf.readIntLE(offset, byteLength[, noAssert]) | 支持读取 48 位以下的有符号数字,小端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| buf.readIntBE(offset, byteLength[, noAssert]) | 支持读取 48 位以下的有符号数字,大端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| buf.toString([encoding[, start[, end]]]) | 根据 encoding 参数(默认是 'utf8')返回一个解码过的 string 类型。还会根据传入的参数 start (默认是 0) 和 end (默认是 buffer.length)作为取值范围。 |
| buf.toJSON() | 将 Buffer 实例转换为 JSON 对象。 |
| buf[index] | 获取或设置指定的字节。返回值代表一个字节,所以返回值的合法范围是十六进制0x00到0xFF 或者十进制0至 255。 |
| buf.equals(otherBuffer) | 比较两个缓冲区是否相等,如果是返回 true,否则返回 false。 |
| buf.compare(otherBuffer) | 比较两个 Buffer 对象,返回一个数字,表示 buf 在 otherBuffer 之前,之后或相同。 |
| buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]]) | buffer 拷贝,源和目标可以相同。 targetStart 目标开始偏移和 sourceStart 源开始偏移默认都是 0。 sourceEnd 源结束位置偏移默认是源的长度 buffer.length 。 |
| buf.slice([start[, end]]) | 剪切 Buffer 对象,根据 start(默认是 0 ) 和 end (默认是 buffer.length ) 偏移和裁剪了索引。 负的索引是从 buffer 尾部开始计算的。 |
| buf.readUInt8(offset[, noAssert]) | 根据指定的偏移量,读取一个无符号 8 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 如果这样 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readUInt16LE(offset[, noAssert]) | 根据指定的偏移量,使用特殊的 endian 字节序格式读取一个无符号 16 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| buf.readUInt16BE(offset[, noAssert]) | 根据指定的偏移量,使用特殊的 endian 字节序格式读取一个无符号 16 位整数,大端对齐。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| buf.readUInt32LE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个无符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readUInt32BE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个无符号 32 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readInt8(offset[, noAssert]) | 根据指定的偏移量,读取一个有符号 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| buf.readInt16LE(offset[, noAssert]) | 根据指定的偏移量,使用特殊的 endian 格式读取一个 有符号 16 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| buf.readInt16BE(offset[, noAssert]) | 根据指定的偏移量,使用特殊的 endian 格式读取一个 有符号 16 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| buf.readInt32LE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readInt32BE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readFloatLE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位双浮点数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| buf.readFloatBE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位双浮点数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| buf.readDoubleLE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位双精度数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.readDoubleBE(offset[, noAssert]) | 根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位双精度数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| buf.writeUInt8(value, offset[, noAssert]) | 根据传入的 offset 偏移量将 value 写入 buffer。注意:value 必须是一个合法的无符号 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则不要使用。默认是 false。 |
| buf.writeUInt16LE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的无符号 16 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeUInt16BE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的无符号 16 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeUInt32LE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式(LITTLE-ENDIAN:小字节序)将 value 写入buffer。注意:value 必须是一个合法的无符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeUInt32BE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式(Big-Endian:大字节序)将 value 写入buffer。注意:value 必须是一个合法的有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeInt8(value, offset[, noAssert]) | |
| buf.writeInt16LE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| buf.writeInt16BE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| buf.writeInt32LE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeInt32BE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeFloatLE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeFloatBE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeDoubleLE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.writeDoubleBE(value, offset[, noAssert]) | 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| buf.fill(value[, offset][, end]) | 使用指定的 value 来填充这个 buffer。如果没有指定 offset (默认是 0) 并且 end (默认是 buffer.length) ,将会填充整个buffer。 |
六、Stream(流)
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http服务器发起请求的request对象就是一个 Stream,还有stdout(标准输出)。
Node.js,Stream 有四种流类型:
Readable - 可读操作。
Writable - 可写操作。
Duplex - 可读可写操作.
Transform - 操作被写入数据,然后读出结果。
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
data - 当有数据可读时触发。
end - 没有更多的数据可读时触发。
error - 在接收和写入过程中发生错误时触发。
finish - 所有数据已被写入到底层系统时触发。
本教程会为大家介绍常用的流操作。
6.1 从流中读取数据
创建 input.txt 文件,内容如下:
1 | Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。 |
创建 stream.js 文件, 代码如下:
1 | var fs = require("fs"); |
以上代码执行结果如下:
程序执行完毕
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
6.2 写入流
修改 stream.js 文件, 代码如下:
1 | var fs = require("fs"); |
以上程序会将 data 变量的数据写入到 output.txt 文件中。代码执行结果如下:
程序执行完毕
写入完成。
查看 output.txt 文件的内容:
wno704官网地址:www.wno704.com
6.3 管道流
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。
我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
以下实例我们通过读取一个文件内容并将内容写入到另外一个文件中。
修改 stream.js 文件, 代码如下:
1 | var fs = require("fs"); |
代码执行结果如下:
程序执行完毕
查看 output.txt 文件的内容:
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
6.4 链式流
链式是通过连接输出流到另外一个流并创建多个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。
修改 stream.js 文件, 代码如下:
1 | var fs = require("fs"); |
代码执行结果如下:
文件压缩完成。
执行完以上操作后,我们可以看到当前目录下生成了 input.txt 的压缩文件 input.txt.gz。
接下来,让我们来解压该文件,修改 stream.js 文件, 代码如下:
1 | var fs = require("fs"); |
代码执行结果如下:
文件解压完成。
执行完以上操作后,我们可以看到当前目录下生成了 input1.txt,
文件内容和input.txt一致。
七、模块系统
为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统。
模块是Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个 Node.js 文件就是一个模块,这个文件可能是JavaScript 代码、JSON 或者编译过的C/C++ 扩展。
7.1 创建模块
在 Node.js 中,创建一个模块非常简单,如下我们创建一个 module.js 文件,代码如下:
1 | var hello = require('./hello'); |
以上实例中,代码 require('./hello') 引入了当前目录下的 hello.js 文件(./ 为当前目录,node.js 默认后缀为 js)。
Node.js 提供了 exports 和 require 两个对象,其中 exports 是模块公开的接口,require 用于从外部获取一个模块的接口,即所获取模块的 exports 对象。
接下来我们就来创建 hello.js 文件,代码如下:
1 | exports.world = function() { |
在以上示例中,hello.js 通过 exports 对象把 world 作为模块的访问接口,在 module.js 中通过 require('./hello') 加载这个模块,然后就可以直接访 问 hello.js 中 exports 对象的成员函数了。
有时候我们只是想把一个对象封装到模块中,格式如下:
1 | module.exports = function() { |
例如:
hello.js
1 | function Hello() { |
这样就可以直接获得这个对象了:
module.js
1 | var Hello = require('./hello'); |
模块接口的唯一变化是使用 module.exports = Hello 代替了exports.world = function(){}。 在外部引用该模块时,其接口对象就是要输出的 Hello 对象本身,而不是原先的 exports。
7.2 服务端的模块放在哪里
也许你已经注意到,我们已经在代码中使用了模块了。像这样:
1 | var http = require("http"); |
Node.js 中自带了一个叫做 http 的模块,我们在我们的代码中请求它并把返回值赋给一个本地变量。这把我们的本地变量变成了一个拥有所有 http 模块所提供的公共方法的对象。
Node.js 的 require 方法中的文件查找策略如下:
由于 Node.js 中存在 4 类模块(原生模块和3种文件模块),尽管 require 方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同。如下图所示: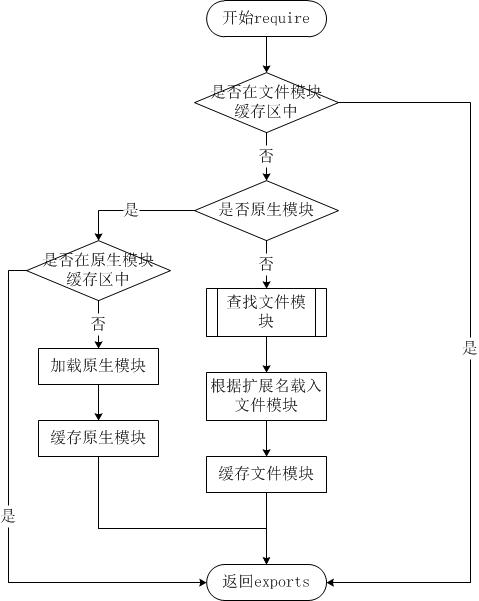
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是都会优先从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require 方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个 http/http.js/http.node/http.json 文件,require("http") 都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js 会解析 require 方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前一节中已经介绍过,这里我们将详细描述查找文件模块的过程,其中,也有一些细节值得知晓。
require方法接受以下几种参数的传递:
*** http、fs、path等,原生模块。
*** ./mod或../mod,相对路径的文件模块。
*** /pathtomodule/mod,绝对路径的文件模块。
*** mod,非原生模块的文件模块。
在路径 Y 下执行 require(X) 语句执行顺序:
1 | 1. 如果 X 是内置模块 |
exports 和 module.exports 的使用
如果要对外暴露属性或方法,就用 exports 就行,要暴露对象(类似class,包含了很多属性和方法),就用 module.exports。
注意:不建议同时使用 exports 和 module.exports。
如果先使用 exports 对外暴露属性或方法,再使用 module.exports 暴露对象,会使得 exports 上暴露的属性或者方法失效。
原因在于,exports 仅仅是 module.exports 的一个引用。在 nodejs 中,是这么设计 require 函数的:
1 | function require(...){ |
八、函数
在 JavaScript中,一个函数可以作为另一个函数的参数。我们可以先定义一个函数,然后传递,也可以在传递参数的地方直接定义函数。
Node.js 中函数的使用与 JavaScript 类似,举例来说,你可以这样做:
1 | function say(word) { |
以上代码中,我们把 say 函数作为 execute 函数的第一个变量进行了传递。这里传递的不是 say 的返回值,而是 say 本身!
这样一来, say 就变成了execute 中的本地变量 someFunction ,execute 可以通过调用 someFunction() (带括号的形式)来使用 say 函数。
当然,因为 say 有一个变量, execute 在调用 someFunction 时可以传递这样一个变量。
8.1 匿名函数
我们可以把一个函数作为变量传递。但是我们不一定要绕这个"先定义,再传递"的圈子,我们可以直接在另一个函数的括号中定义和传递这个函数:
1 | function execute(someFunction, value) { |
我们在 execute 接受第一个参数的地方直接定义了我们准备传递给 execute 的函数。
用这种方式,我们甚至不用给这个函数起名字,这也是为什么它被叫做匿名函数 。
8.2 函数传递是如何让HTTP服务器工作的
带着这些知识,我们再来看看我们简约而不简单的HTTP服务器:
1 | var http = require("http"); |
现在它看上去应该清晰了很多:我们向 createServer 函数传递了一个匿名函数。
用这样的代码也可以达到同样的目的:
1 | var http = require("http"); |
九、路由
我们要为路由提供请求的 URL 和其他需要的 GET 及 POST 参数,随后路由需要根据这些数据来执行相应的代码。
因此,我们需要查看 HTTP 请求,从中提取出请求的 URL 以及 GET/POST 参数。这一功能应当属于路由还是服务器(甚至作为一个模块自身的功能)确实值得探讨,但这里暂定其为我们的HTTP服务器的功能。
我们需要的所有数据都会包含在 request 对象中,该对象作为 onRequest() 回调函数的第一个参数传递。但是为了解析这些数据,我们需要额外的 Node.JS 模块,它们分别是 url 和 querystring 模块。
1 | url.parse(string).query |
当然我们也可以用 querystring 模块来解析 POST 请求体中的参数,稍后会有演示。
现在我们来给 onRequest() 函数加上一些逻辑,用来找出浏览器请求的 URL 路径:
server.js 文件代码:
1 |
|
好了,我们的应用现在可以通过请求的 URL 路径来区别不同请求了--这使我们得以使用路由(还未完成)来将请求以 URL 路径为基准映射到处理程序上。
在我们所要构建的应用中,这意味着来自 /start 和 /upload 的请求可以使用不同的代码来处理。稍后我们将看到这些内容是如何整合到一起的。
现在我们可以来编写路由了,建立一个名为 router.js 的文件,添加以下内容:
router.js 文件代码:
1 | function route(pathname) { |
如你所见,这段代码什么也没干,不过对于现在来说这是应该的。在添加更多的逻辑以前,我们先来看看如何把路由和服务器整合起来。
我们的服务器应当知道路由的存在并加以有效利用。我们当然可以通过硬编码的方式将这一依赖项绑定到服务器上,但是其它语言的编程经验告诉我们这会是一件非常痛苦的事,因此我们将使用依赖注入的方式较松散地添加路由模块。
首先,我们来扩展一下服务器的 start() 函数,以便将路由函数作为参数传递过去,server.js 文件代码如下
server.js 文件代码:
1 |
|
同时,我们会相应扩展 index.js,使得路由函数可以被注入到服务器中:
index.js 文件代码:
1 |
|
在这里,我们传递的函数依旧什么也没做。
如果现在启动应用(node index.js,始终记得这个命令行),随后请求一个URL,你将会看到应用输出相应的信息,这表明我们的HTTP服务器已经在使用路由模块了,并会将请求的路径传递给路由:
Server has started.
以上输出已经去掉了比较烦人的 /favicon.ico 请求相关的部分。
浏览器访问 http://127.0.0.1:8888 ,输出结果如下: