一、前言 在 《浅谈分库分表》 一文中,我们介绍了分库分表的思想,这节我们介绍ShardingJdbc的分库和分表实现,了解更多可参考 官方文档 。
二、基础知识 2.1 逻辑表 逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户sex%2+1拆分为2个表,分别是:t_staff1和t_staff2。他们的逻辑表名是:t_staff。
1 2 3 4 5 6 spring: shardingsphere: sharding: default-data-source-name: ds0 # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 tables: # 配置分表的规则 t_staff:
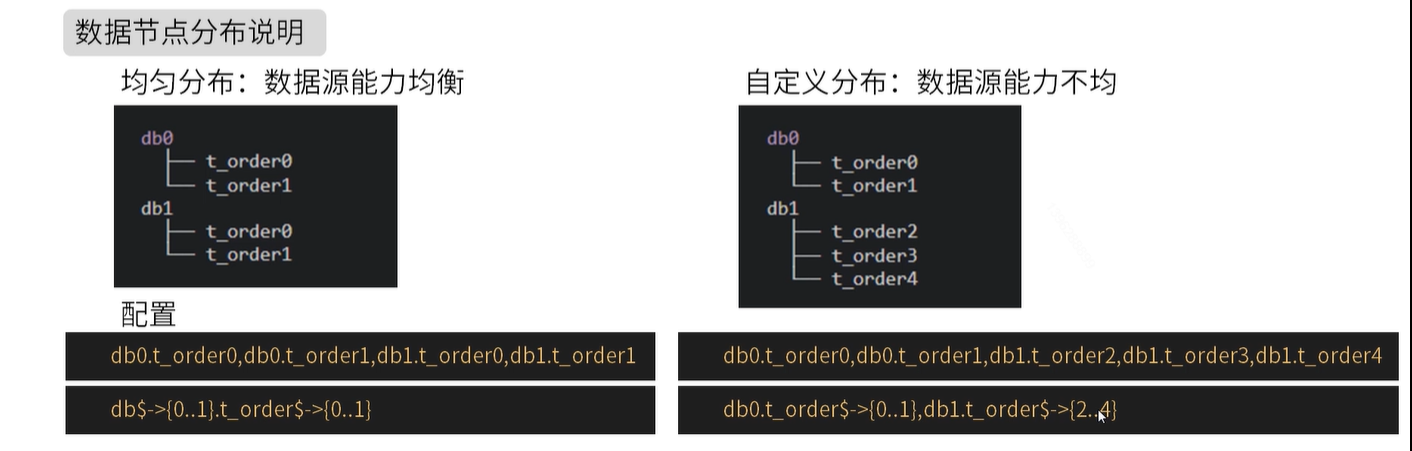
2.2 分库分表数据节点 - actual-data-nodes 1 2 3 4 5 6 tables: t_staff: # t_staff 逻辑表名 actual-data-nodes: ds$->{0..2}.t_staff$->{1..2} # 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 相同表 actual-data-nodes: ds0.t_staff$->{1..2},ds1.t_staff$->{2..4} # 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 不同表 actual-data-nodes: ds0.t_staff$->{1..2} # 指定单数据源的配置方式 actual-data-nodes: ds0.t_staff1,ds1.t_staff1,ds0.t_staff2,ds1.t_staff2, # 全部手动指定
数据分片是最小单元。由数据源名称和数据表组成,比如:ds0.t_staff1。
2.3 数据源分片分
这两个是不同维度的分片规则,但是它们额能用的分片策略和规则是一样的。它们由两部分构成:
2.4 分库分表5种分片策略 2.4.1 none 对应NoneShardingStragey,不分片策略,SQL会被发给所有节点去执行,这个规则没有子项目可以配置。
2.4.2 inline 行表达时分片策略 对应InlineShardingStragey。使用Groovy的表达时,提供对SQL语句种的=和in的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开放,如:t_staff${分片键(数据表字段)sex % 2 + 1} 表示t_staff表根据某字段(sex)模 2.从而分为2张表,表名称为:t_staff1到t_staff2 。如果库也是如此。
algorithm-expression行表达式:
${begin..end} 表示区间范围。
${[unit1,unit2,….,unitn]} 表示枚举值。
行表达式种如果出现连续多个${expresssion}或$->{expression}表达式,整个表达时最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
2.4.3 标准分片 - Standard 对应StrandardShardingStrategy.提供对SQL语句中的=,in和恶between and 的分片操作支持。
StrandardShardingStrategy只支持但分片键。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
PreciseShardingAlgorithm是必选的呃,用于处理=和IN的分片
和RangeShardingAlgorithm是可选的,是用于处理Betwwen and分片,如果不配置和RangeShardingAlgorithm,SQL的Between AND 将按照全库路由处理。
2.4.4 complex 符合分片策略 对应接口:HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
对于分片字段非SQL决定,而是由其他外置条件决定的场景,克使用SQL hint灵活的注入分片字段。例如:按照用户登录的时间,主键等进行分库,而数据库中并无此字段。SQL hint支持通过Java API和SQL注解两种方式使用。让后分库分表更加灵活。
2.4.5 hint分片策略 对应ComplexShardingStrategy。符合分片策略提供对SQL语句中的-,in和between and的分片操作支持。
ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键组合以及分片操作符透传至分片算法,完全由开发者自己实现,提供最大的灵活度。
2.5 分布式主键配置 ShardingSphere提供灵活的配置分布式主键生成策略方式。在分片规则配置模块克配置每个表的主键生成策略。默认使用雪花算法。(snowflake)生成64bit的长整型数据。支持两种方式配置
SNOWFLAKE
UUID
注意:主键列不能自增长。数据类型是:bigint(20)
2.6 事务管理 官方地址:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/function/base-transaction-seata/
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/usage/transaction/
2.6.1 数据库事务需要满足ACID(原子性、一致性、隔离性、持久性)四个特性 原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行。
一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态。
隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability)指已提交的事务修改数据会被持久保存。
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
2.6.2 本地事务 在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。 它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
2.6.3 两阶段提交 XA协议最早的分布式事务模型是由X/Open国际联盟提出的X/Open Distributed Transaction Processing(DTP)模型,简称XA协议。
2.6.4 柔性事务 如果将实现了ACID的事务要素的事务称为刚性事务的话,那么基于BASE事务要素的事务则称为柔性事务。 BASE是基本可用、柔性状态和最终一致性这三个要素的缩写。
2.6.5 事务的几种类型 本地事务
完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交。
两阶段XA事务
支持数据分片后的跨库XA事务
两阶段提交保证操作的原子性和数据的强一致性
服务宕机重启后,提交/回滚中的事务可自动恢复
SPI机制整合主流的XA事务管理器,默认Atomikos,可以选择使用Narayana和Bitronix
同时支持XA和非XA的连接池
提供spring-boot和namespace的接入端
不支持:
服务宕机后,在其它机器上恢复提交/回滚中的数据
Seata柔性事务
完全支持跨库分布式事务
支持RC隔离级别
通过undo快照进行事务回滚
支持服务宕机后的,自动恢复提交中的事务
依赖:
需要额外部署Seata-server服务进行分支事务的协调
待优化项
ShardingSphere和Seata会对SQL进行重复解析
三、代码实战 3.1 基础代码 下面具体分表分库等实践使用如下基础代码:
3.1.1 依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.6.1</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.wno704</groupId> <artifactId>sharding</artifactId> <version>0.0.1-SNAPSHOT</version> <name>sharding</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.6</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-core-common</artifactId> <version>4.0.0-RC1</version> </dependency> <dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-transaction-spring-boot-starter</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
3.1.2 基础代码 Staff.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Data public class Staff { private Integer id; private String name; private String password; private Integer sex; private String birthday; }
StaffService.java
1 2 3 4 5 6 public interface StaffService { int add(Staff staff); List<Staff> findStaff(); }
StaffServiceImpl.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Service("staffService") public class StaffServiceImpl implements StaffService { @Autowired private StaffMapper staffMapper; @Override public int add(Staff staff) { return staffMapper.addSraff(staff); } @Override public List<Staff> findStaff() { return staffMapper.findStaff(); } }
StaffMapper.java
1 2 3 4 5 6 7 8 9 10 @Component @Mapper public interface StaffMapper { @Insert("insert into t_staff(name,password,sex,birthday) values(#{name},#{password},#{sex},#{birthday})") int addSraff(Staff staff); @Select("select * from t_staff") List<Staff> findStaff(); }
StaffController.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @RestController @RequestMapping("/api/staff") public class StaffController { @Autowired private StaffService staffService; @GetMapping("/save") public String insert(){ Staff staff = new Staff(); staff.setName("wno704-"+new Random(10).nextInt()); staff.setPassword("kU@jwN8qJh4GulI&P1xZ"); staff.setSex(new Random().nextInt(10)%2); staff.setBirthday("1992-05-03"); staffService.add(staff); return "succ"; } @GetMapping("/saveStaff") public String saveStaff(Staff staff){ staffService.add(staff); return "succ"; } @GetMapping("/list") public List<Staff> listStaff(){ return staffService.findStaff(); } }
3.2 inline 分片策略实践 3.2.1 数据库新建如下表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 CREATE TABLE `t_staff1` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `sex` int(2) NULL DEFAULT NULL, `birthday` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_staff2` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `sex` int(2) NULL DEFAULT NULL, `birthday` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
3.2.2 配置 application.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 spring: main: allow-bean-definition-overriding: true shardingsphere: props: sql: show: true datasource: names: ds0,ds1 ds0: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 sharding: default-data-source-name: ds0 # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 tables: # 配置分表的规则 t_staff: # t_staff 逻辑表名 actual-data-nodes: ds$->{0..1}.t_staff$->{1..2} # 数据节点:数据源$->{0..N}.逻辑表名$->{0..N} database-strategy: # 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。 inline: sharding-column: sex # 分片字段(分片键) algorithm-expression: ds$->{sex % 2} # 分片算法表达式 table-strategy: # 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。 inline: sharding-column: sex # 分片字段(分片键) algorithm-expression: t_staff$->{sex % 2 + 1} # 分片算法表达式
3.2.3 测试 多次访问 http://127.0.0.1:8080/api/staff/save
控制台日志如下:
数据库保存数据如下:
这个时候执行查询 http://127.0.0.1:8080/api/staff/list
后台日志如下:
通过上面日志发现,根据sex的不同,数据分别插入到不同的数据源、不同的表里面。在我们查询时候,sql语句查询是逻辑表,实际查询了所有的表。
3.3 Standard 分片策略实践 3.3.1 数据库新建如下表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 CREATE TABLE `t_staff3` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `sex` int(2) NULL DEFAULT NULL, `birthday` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_staff4` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `sex` int(2) NULL DEFAULT NULL, `birthday` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
3.3.2 配置 application.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 spring: main: allow-bean-definition-overriding: true shardingsphere: props: sql: show: true datasource: names: ds0,ds1 ds0: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 sharding: default-data-source-name: ds0 # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 tables: # 配置分表的规则 t_staff: # t_staff 逻辑表名 actual-data-nodes: ds$->{0..1}.t_staff$->{1..2} # 数据节点:数据源$->{0..N}.逻辑表名$->{0..N} database-strategy: # 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。 standard: sharding-column: birthday # 分片字段(分片键) preciseAlgorithmClassName: com.wno704.boot.algorithm.BirthdayAlgorithm table-strategy: # 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。 standard: sharding-column: sex # 分片字段(分片键) preciseAlgorithmClassName: com.wno704.boot.algorithm.SexAlgorithm
3.3.3 拆分库策略 BirthdayAlgorithm.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class BirthdayAlgorithm implements PreciseShardingAlgorithm<String> { Map<String, String> mp = new HashMap<>(); { mp.put("2019","ds0"); mp.put("2020","ds0"); mp.put("2021","ds1"); mp.put("2022","ds1"); } @Override public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) { // 获取属性数据库的值 String birthday = preciseShardingValue.getValue(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); SimpleDateFormat formatter = new SimpleDateFormat("yyyy"); Date date = null; String target = null; try { date = simpleDateFormat.parse(birthday); String year = formatter.format(date); target = mp.get(year); } catch (ParseException e) { e.printStackTrace(); } return target; } }
3.3.4 拆分表策略 SexAlgorithm.java
1 2 3 4 5 6 7 8 9 10 public class SexAlgorithm implements PreciseShardingAlgorithm<Integer> { @Override public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) { String tbName = preciseShardingValue.getLogicTableName() + (preciseShardingValue.getValue()%2+1 ); System.out.println("Sharding input:" + preciseShardingValue.getValue() + ", output:{}" + tbName); return tbName; } }
3.3.5 测试 分别访问
http://127.0.0.1:8080/api/staff/saveStaff?name=wno704001&password=dssdmksdmwemk232dsd&sex=1&birthday=2021-03-09
http://127.0.0.1:8080/api/staff/saveStaff?name=wno704001&password=dssdmksdmwemk232dsd&sex=2&birthday=2021-03-09
http://127.0.0.1:8080/api/staff/saveStaff?name=wno704001&password=dssdmksdmwemk232dsd&sex=1&birthday=2019-03-09
http://127.0.0.1:8080/api/staff/saveStaff?name=wno704001&password=dssdmksdmwemk232dsd&sex=2&birthday=2019-03-09
后台日志如下:
通过上面分析发现birthday为2021会选择数据源ds1,2019会选择数据源ds0。sex为1会保存到t_staff2表,2会保存到t_staff1表里。
3.4 主键配置 3.4.1 配置 application.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 spring: main: allow-bean-definition-overriding: true shardingsphere: props: sql: show: true datasource: names: ds0,ds1 ds0: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/springboot?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: spring password: spring#123 maxPoolSize: 100 minPoolSize: 5 sharding: default-data-source-name: ds0 # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 tables: # 配置分表的规则 t_staff: # t_staff 逻辑表名 key-generator: column: id type: SNOWFLAKE # UUID SNOWFLAKE actual-data-nodes: ds$->{0..1}.t_staff$->{3..4} # 数据节点:数据源$->{0..N}.逻辑表名$->{0..N} database-strategy: # 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。 inline: sharding-column: sex # 分片字段(分片键) algorithm-expression: ds$->{sex % 2} # 分片算法表达式 table-strategy: # 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。 inline: sharding-column: sex # 分片字段(分片键) algorithm-expression: t_staff$->{sex % 2 + 3} # 分片算法表达式
3.4.2 测试 多次访问 http://127.0.0.1:8080/api/staff/save
后台日志如下:
通过日志发现,sql中会自动给我们拼接id字段。
注意: 在指定主键的情况下,数据库表主键对应的字段一定不能设置为自动递增,不然执行时候会报错。
3.5 事务使用 3.5.1 代码 我们在StaffController.java 增加如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @GetMapping("/saveTrans") @ShardingTransactionType(TransactionType.XA) @Transactional(rollbackFor = Exception.class) public String saveTrans(){ Staff staff = new Staff(); staff.setName("wno704-Transactional"); staff.setPassword("kU@jwN8qJh4GulI&P1xZ"); staff.setSex(new Random().nextInt(10)%2); staff.setBirthday("1992-05-03"); staffService.add(staff); int a = 1/0; //测试回滚 return "succ"; }
3.5.2 测试 访问 http://127.0.0.1:8080/api/staff/saveTrans
后台日志如下:
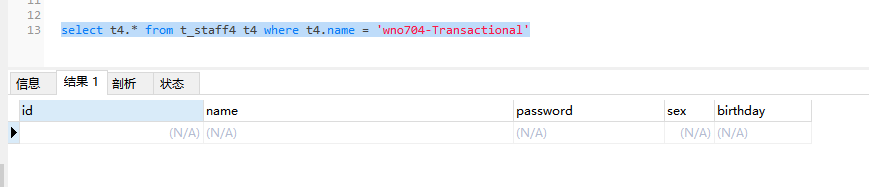
数据库在t_staff4表通过name查询结果如下:
查询数据库后,发现实际数据并未插入,说明事务生效了。