

一、前言
在实际的业务开发中经常会遇到以下问题,业务系统B需要尽可能实时获取业务系统A的数据,业务系统B对应的持久化使用mysql数据库,业务系统A使用oracle数据库。这里我使用了quartz作为定时任务框架,定时从A库不断抽取数据到B库中,实际业务中我们往B库中抽取的来源系统比较多。quartz搭建参考 《Spring Boot整合Quartz》 。但是在实际抽取过程中我们发现定时框架配置的抽取间隔不是我们配置的,比如我的定时器间隔是10分钟,实际抽取的时间总是提前或者滞后几秒。这样就导致了抽取的数据和原系统的不一致,总是导致缺数据或者重复数据。为此我从网上百度,找到了以下解决方案。
二、问题解决方案
如果我们在B库中设置了唯一索引,那么在插入重复数据时,SQL 语句将无法执行成功,并抛出错。
INSERT IGNORE INTO 与 INSERT INTO 的区别就是 INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。INSERT IGNORE INTO 当插入数据时,在设置了记录的唯一性后,如果插入重复数据,将不返回错误,只以警告形式返回。 而 REPLACE INTO 如果存在 primary 或 unique 相同的记录,则先删除掉。再插入新记录。
2.1 创建表,插入数据
1 | CREATE TABLE users |
2.2 insert
插入已存在, id会自增,但是插入不成功,会报错
1 | insert into users(name, age) values("小明", 23); |
insert into users(name, age) values("小明", 23)
1062 - Duplicate entry '小明' for key 'name'
时间: 0.002s
2.3 replace
已存在替换,删除原来的记录,添加新的记录
1 | replace into users(name, age) values("小明", 23); |
replace into users(name, age) values("小明", 23)
OK
时间: 0.003s
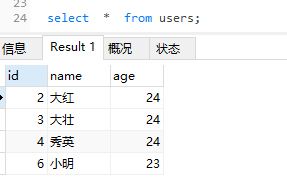
不存在替换,添加新的记录
1 | replace into users(name, age) values("大名", 23); |
replace into users(name, age) values("大名", 23)
OK
时间: 0.003s
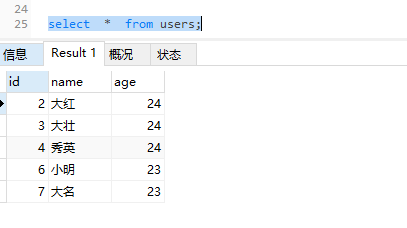
2.4 insert ignore
插入已存在,忽略新插入的记录,id会自增,不会报错
1 | insert ignore into users(name, age) values("大壮", 25); |
insert ignore into users(name, age) values("大壮", 25)
Affected rows: 0
时间: 0.001s
插入不存在,添加新的记录
1 | insert ignore into users(name, age) values("壮壮", 25); |
insert ignore into users(name, age) values("壮壮", 25)
Affected rows: 1
时间: 0.004s

